Instagram Bots
January 21, 2020
Update, November 2020:The Wikipedia Picture of the Day bot is now active again on Twitter, which has a much more permissive API—one which I would highly recommend working with. There is also a companion bot, POTD context.
Over the course of 2019, I built and deployed two Instagram bots, @wikipictureoftheday and @wacky_minions. @wikipictureoftheday had a relatively simple concept: Pull the Wikipedia picture of the day and post it to Instagram at regular intervals. It ended up making a pretty compelling feed, with plenty of interesting facts and photography, but never took off in popularity.
@wacky_minions, on the other hand, blew up. The account sources random images of Minions from Google Images and builds a caption using a Minion-themed caption generator I designed. At its peak, I was gaining 500 followers a week and posting more than eight times every day to an audience that now exceeds nearly 7,000 users. The content was simple, but clearly popular. Following the account meant Minion posts would instantly take over your feed.
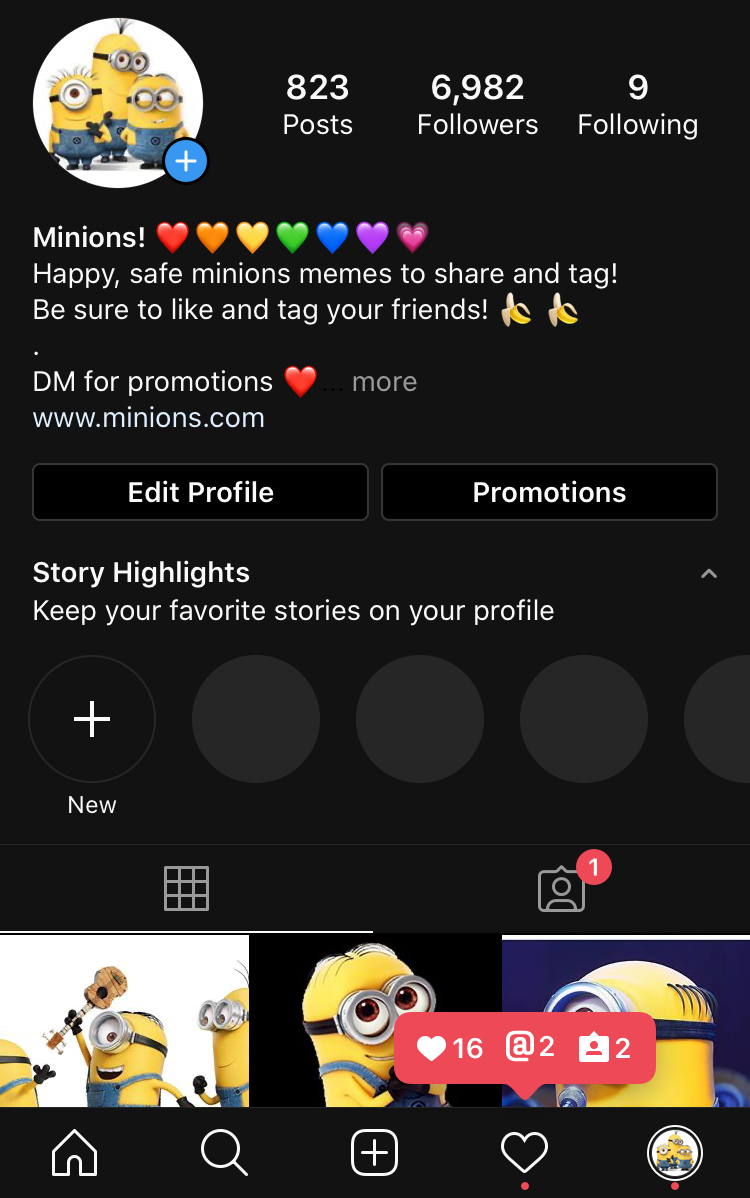
Both accounts are now offline—since their inception, Instagram has changed their API accessibility, and now, an Instagram API is all but nonexistent. The decision to remove API accessibility is likely part of a larger crackdown on Instagram bots, especially content like @wacky_minions, but Instagram's restrictions on API access began in 2018 as a response to the Cambridge Analytica scandal. The decision to remove API access on Instagram is incredibly disappointing. For one, it means that engaging content like @wikipictureoftheday is nearly impossible to publish anymore. It also means that it is far more difficult to retrieve data from Instagram as an end user, meaning the outside world is unable to understand the data that Instagram can and does collect from their users. In other industries, there are laws protecting the public's right to retrieve data; take, for example, Seattle's bike share program, which requires operators to provide SDOT with real-time information on their entire fleet through an API.
Beyond limiting general access to their API, Instagram is also limiting the data they present to their end users. Instagram is rolling a new plan to hide like counts from users, which will soon be a default on the app. While this is good news as a counter for the modern influencer economy, it is also another way for Instagram to hide previously public user data. The decision further obfuscates the algorithm used to insert images into user feeds, making it easier for larger brands to silently move up in the ranks, putting their images first in line when you open the app. This makes it far more accessible to build invisible and manipulable echo chambers of information. If the number of likes a post is receiving is hidden, it's impossible to tell whether it's content that's been shown to thousands of other users or just a dozen. Movements (political or otherwise) with little traction will have even more difficulty finding a larger audience, leading to an implicit suppression of ideas.
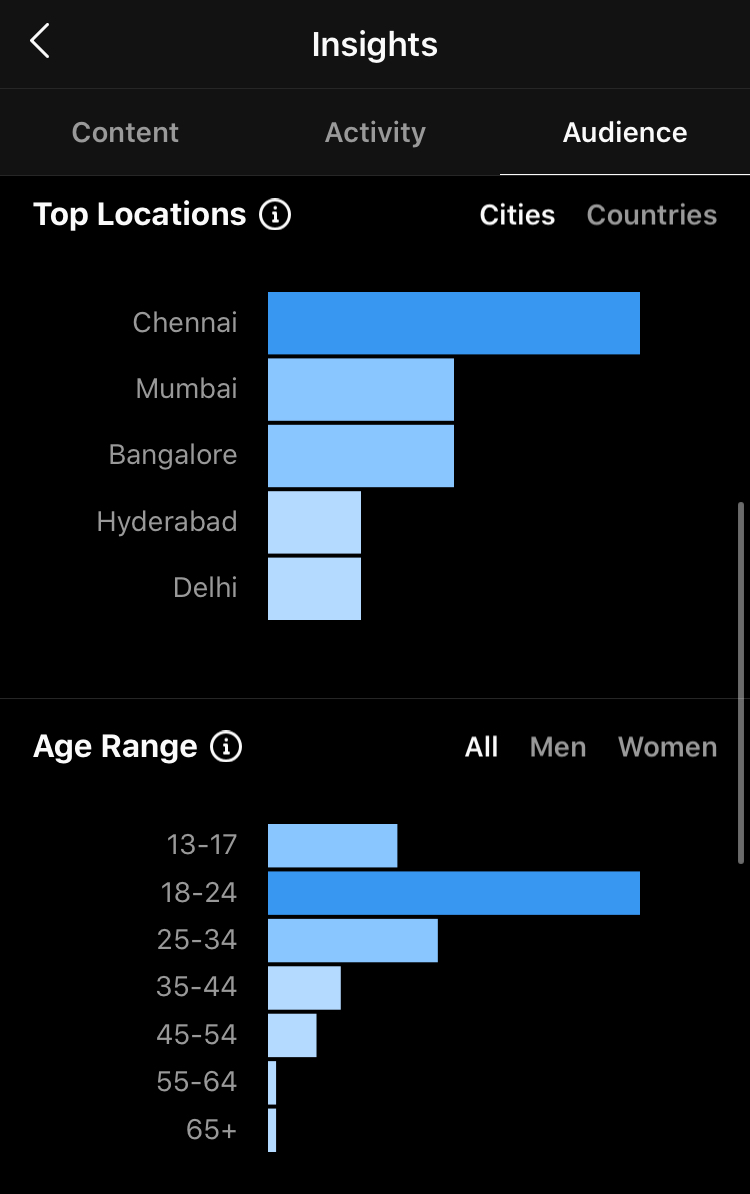
Certain kinds of data transparency, especially from private companies, are very important. As I operated @wacky_minions, I transitioned from a standard user account to a business account. There, I was offered general analytics on my user base, which detailed information including the cities my followers are located in, their age range, gender ratio, and activity patterns. It's unclear whether this aggregate data includes information about private accounts. (Business users can't see individual personal information, only aggregate information. Of course, it is internally possible for Instagram to pinpoint specific user data, which is scary of its own right.)
These two concerns—an interest in transparency of information from the companies collecting data and an interest in protecting user privacy—are inherently at ends with one another. It's incredibly difficult to realize a solution to both at the same time. But information access models like that of Twitter, which requires users to submit a processed request in order to obtain API access, put a tap on the accessibility of data. Moreover, only information users make public (for example, content produced by accounts that have opted in to being public) should be available. This information should be a legal right: Users should have access to the public data on social media. Likewise, users should be able to automate content posting, allowing for content possible only from a bot. From there, let the users decide whether they want to follow those accounts—even if it sometimes means letting nonsense accounts like @wacky_minions end up far more popular than serious accounts like @wikipictureoftheday.